
















Schema evolution is a crucial aspect that has been considered in today’s complex world of managing data pipelines. Due to new data sources and frequent updates, the database schema changes and possible schema drifts in turn cause problems in terms of operations, data quality, and decision-making. This article examines the best practices implemented to address schema changes, aiming to improve pipeline efficiency, data accuracy, and flexibility, thereby helping organizations meet the evolving needs of their data.
Schema Evolution in Data Pipelines
Schema evolution is the process that defines the change in the structure of data as it goes through the system pipeline. Schema changes are, thus, inevitable in current data systems, as the sources of data, the uses to which the data are put, and the technologies supporting the systems change over time. This change can involve extending the structure by either adding new fields, deleting some fields that may be irrelevant in today’s business world, or modifying the type of some existing fields already included in the structure.
Key points to understand:
- Dynamic Changes: When adding new data repository information, this organization may need to modify the schema to accommodate the differences in format and structure.
- Continuous Business Needs: Data pipelines should remain relevant to changing business logic and analysis, as well as accommodate schema changes.
- Technological Advancements: As more advanced technologies are developed, the formats of data also evolve, requiring new schemas to accommodate the latest formats.
The Role of Schema Evolution in Data Pipeline Management
Schema evolution is the process of handling changes made to the data structure being used in a data pipeline and is very important in data pipeline management. When it comes to storing data, structures also evolve in tandem with the systems as they become more sophisticated. Solutions may involve modifying the database, as this could be prompted by business needs, data source availability, or technological advancements that affect the movement of data through a pipeline. These changes, if not managed effectively, can disrupt the flow, leading to data discrepancies, integration issues, and complications.
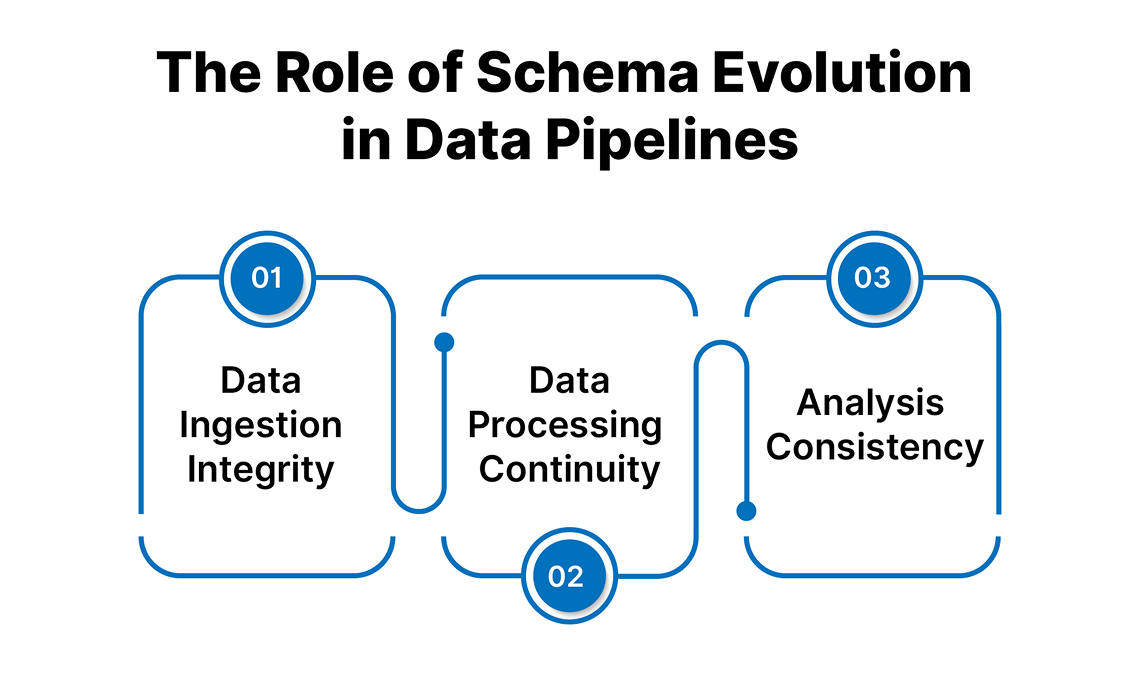
Reasons why the schema evolution is crucial in the management of a data pipeline:
- Data Ingestion Integrity: When a new field or data type is introduced, pipelines must handle the challenge of accurately and efficiently extracting and storing the necessary data. Some of the poor outcomes of not effectively handling schema changes include receiving a partial or incorrect dataset.
- Data Processing Continuity: Changes to the database schema pose a challenge to downstream operations, such as transformation and aggregation. Such changes should not affect the time it takes to process the information or compromise the accuracy of the results.
- Analysis Consistency: A key for data analysts and data scientists is the consistency of the schema in the analysis and presentation of data. These breaches of schema evolution may introduce inconsistency issues that affect business intelligence.
Types of Schema Evolution and Common Scenarios
Schema modification in a database refers to the changes made to the database's structure in an attempt to meet new demands or enhance the performance of a given system. Since the use of data sources is extensive and business needs are constantly changing, adjustments to the schema are necessary. Evaluating the types of schema evolution and the conditions under which they occur is crucial for maintaining the health of a proper data pipeline.
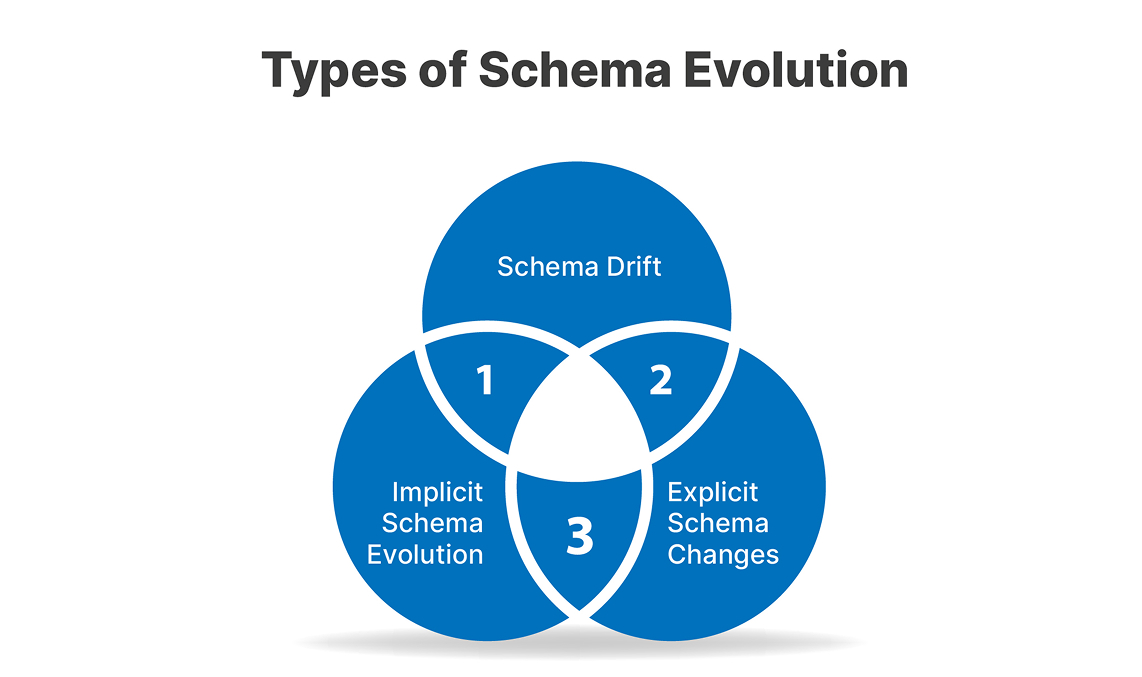
1. Schema Drift
Schema drift refers to the gradual evolution of a schema or data structure without undergoing a formal versioning process. Lack of proper management can lead to data corruption or even processing errors. This is a common issue that occurs when data is ingested from various data sources, and the schemas of some layers in the stack may not be aligned.
Example: A field may be inserted in a single element of the pipeline but may not be propagated to all aspects of the system, resulting in inconsistency during subsequent analysis.
2. Explicit Schema Changes
These are purposeful changes to the schema to accommodate new attributes, such as creating new columns, modifying the data type of similar or different tables, and so on. These tasks are typically performed during maintenance or when implementing a new system.
Example: An organization might require the creation of a “region” field when collecting customer data for a new geographic location that the organization is venturing into.
3. Implicit Schema Evolution
Implicit changes occur when the data structure changes are sensed and adapted without the need for developer intervention through the use of dynamic data types or scalability frameworks. This type of evolution is effective in preventing interruptions to the pipeline, but should be accompanied by thorough scrutiny to ensure accuracy.
Best Practices for Handling Schema Evolution in Data Pipelines
Managing schema evolution is crucial for adaptive and efficient data pipeline management systems. As data systems expand in size and functionality, organizations are required to implement more effective and efficient measures to handle database schema modifications that are common in typical applications.
Implementation begins with schema versioning, as multiple versions of the schema can be used to process both older and newer data while maintaining compatibility. This practice helps sustain the routine deployment of changes with minimal interruption.
- Forward and backward compatibility should be ensured by allowing new versions of the schema to add new fields or rearrange existing fields in any order, without compromising the schema's integrity. This strategy ensures that the various components of the pipeline do not break down on completion of their work.
- Schema validation frameworks should be incorporated at all stages of the pipeline. For the occurrence of schema changes to be identified early and avoid corrupted data being ingested into our system, validation is helpful.
- Schema change creation and management should also be automated to enable faster responses and lower the occurrence of mistakes. In this way, we can use automated tools that identify incompatible changes and notify relevant personnel for further review.
Case Studies and Real-World Examples
Managing schema changes and preventing schema drift are crucial factors to address when working with data pipelines. Many organizations have developed practical techniques to address problems associated with changes to the database schema of data.
- KOHO Financial Inc.: A Canadian startup in the fintech industry struggled with issues around high amounts of schema drift in the pipelines. To this effect, KOHO maintained the dataset catalogs on the table to facilitate the tracking of schema changes and the subsequent updating of the table structures in the data warehouse. It made it possible for data consumers to access the freshest datasets within the system without involving other people.
- Upsolver: In cases where the source data changes over time and new fields are added, modified, or deleted, Upsolver has proven to be able to handle changes in the schema. Their system enables the creation of new schemas from source data. It provides methods for updating output tables in the event of changes to a schema, whether through alterations or the addition of new tables.
- Onehouse: One of the challenges facing Onehouse due to data lakehouse architecture was coping with changes to the underlying schema of many related database tables. This approach eliminates data pipeline issues and preserves data integrity during schema development.
Conclusion
The problem of schema evolution in data pipeline management is analyzed in terms of managing database schema changes and their associated structural requirements. Incorporating best practices like versioning, compatibility handling, schema validation, and real-time monitoring helps organizations stay agile. The prevention of schema drift using frameworks and lineage management helps round off data protection, allowing teams to grow at scale while maintaining optimal efficiency.














