
















The growth of ecommerce in the recent past can only be described as explosive and sweeping across the planet. According to a 2016 study, half of all dollars spent online in America belong to Amazon.
And consider this, Recommendation Engines alone drive 35% of that revenue.
But it is not ecommerce alone that’s reaping the huge benefits that recommendation engines have to offer. Direct to device streaming services such as Netflix, Spotify among others, analyze user behavior almost to a micro moment level, then gather data surrounding similar users who are likely to buy the same items based on their browsing history, and provide that much needed nudge to move on to the next purchase on the platform. Streaming services, on the other hand, have their hands full on customizing content that the viewer is anticipated to consume next, based on the algorithms that classify the metadata on each content piece, and then presenting it to the user. Indeed, if ecommerce giants are predicting user behavior, streaming services and their ilk have taken over media consumption to the next level, driven by the power of suggestion and influence, hyper-personalized to each user’s preferences. At the heart of their success and growth is the collection of algorithms and code we call recommendation engines. Not all recommender systems are the same, however.
The CategoriesThe two most widespread recommendation systems prevalent in the Machine Learning world today serve to major market segments:
Collaborative Filtering - Used largely by ecommerce players, the primary assumption in collaborative filtering is that customers who have shown certain behavioral patterns, purchase or otherwise, will see continue to exhibit the same pattern and choices throughout the duration of their lifetime value, and other users with the same pattern will exhibit the same behavior. The method of collaborative comprises several steps:
- Data Collection
- Storage and Classification
- Filtering by Algorithms
- Items Matching
- Predictive Analytics
Content Based Filtering - Content based filtering refers to the analysis of the content that a particular user is interested in, based on the assumption that their cohorts would be interested in the same content and thus a suggestion or recommendation based on the same content filters would enable a greater degree of acceptance among users who have set the same metatag in their preference, identified, of course, by the system.
The Mechanics of Recommender Systems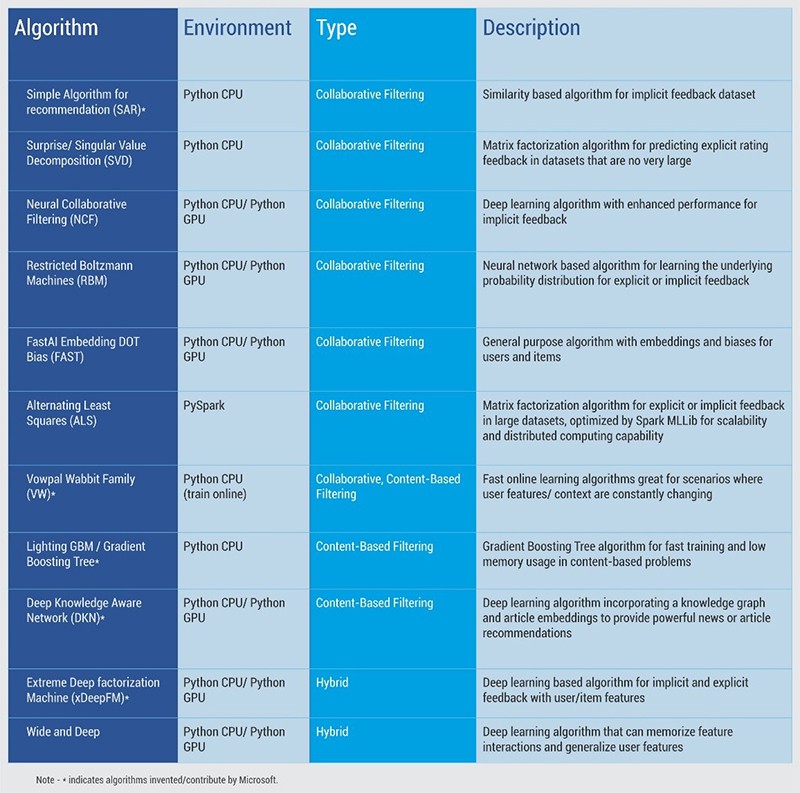
Overall, the steps included in implementing recommendation engines on both the platforms include:
Recommendation Phases and Structuring:
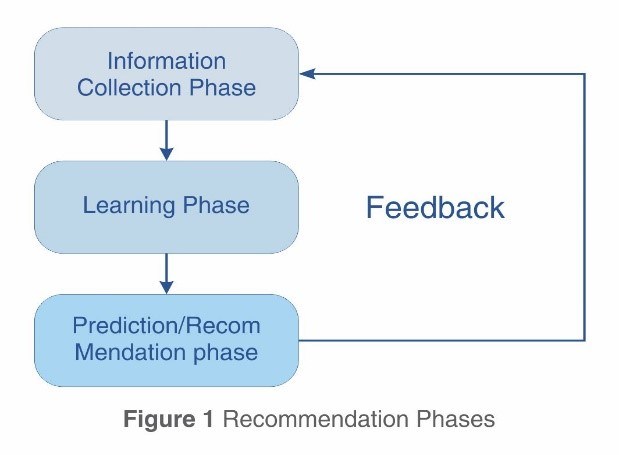
Recommendation phases to create the basis of the recommendation engine inputs.
The Stages in RecommendationInformation Collection Phase: Collects relevant data from a user to generate a user profile. This includes attributes, behaviors and the content that the user accesses. This system can only be constructed when it has enough relevant data on the user profile. The primary mechanism of this is through feedback, of which there are two kinds:
Explicit feedback - This is usually garnered from system prompts on the user interface, including ratings for items to construct and fine-tune the model.
Implicit feedback - In this model, whose use is widespread in ecommerce and streaming services, the system draws conclusions on the user profile by thorough monitoring of user actions including purchase history, navigation history, time spent on web pages and links followed, including links clicked in email campaigns.
Learning Phase: In this stage, the learning system algorithm is deployed to ensure that the model is able to filter the user’s attributes from the feedback gathered in the previous phases.
A simple sample algorithm is shown below:

In this phase, the model predicts the choices of the user, or recommends items that the user would most probably prefer. The two sources considered are either a fixed dataset from the information collection phase, or a memory based model which relies on the system’s inferences from the users’ behavior.
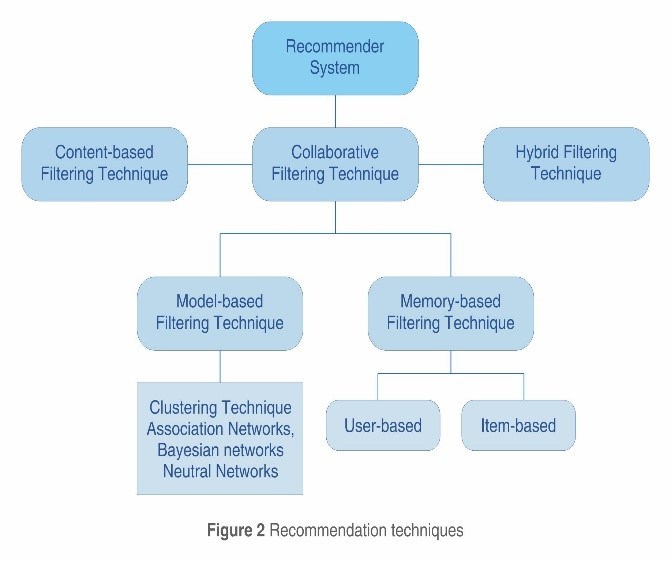
Hierarchy depicting the different techniques used by recommendation systems.
The Techniques Recommendation filteringIt is vital to use accurate recommendation techniques for the model to provide useful recommendations and information to the users. The classifications of these filtering techniques are explained as below:
Content Based FilteringContent based filtering is usually domain specific dependent algorithm. Its key emphasis is on the analysis of the attributes of the items (not users) to generate recommendations and predictions. This is mostly applicable to content based consumption by the user. In content based filtering, recommendations are made to the user based on feature extraction of the content that the user consumes or has evaluated in the past. Recommendations are made based on the attributes of the content, not the user, using features extracted from the content. Content based filtering offers different types of models to establish similar patterns to generate meaningful and useful recommendations. Some of the commonly used models include Vector Space Model, like Term Frequency, Inverse Document Frequency, Or even Naive Bayes Classifiers, Neural Networks or Decision Trees. Sometimes even Neural Networks are used. The most important aspect of content based filtering is ensuring that the meta information on the items are as close a match as possible to user attributes.
The Collaborative Filtering ProcessCollaborative Filtering is the method of a domain independent prediction strategy that is not usually based on item attribution as in the case of content based filtering. Collaborative filtering usually works with a database build of a user-item preference matrix and then matches users with preferences and interests that may appeal to them using matching similarities to make recommendations. The user gets recommendations to those items that he has not rated before but that were already positively rated by users in his neighborhood. Recommendations that are produced by collaborative filtering can be of either prediction or recommendation.
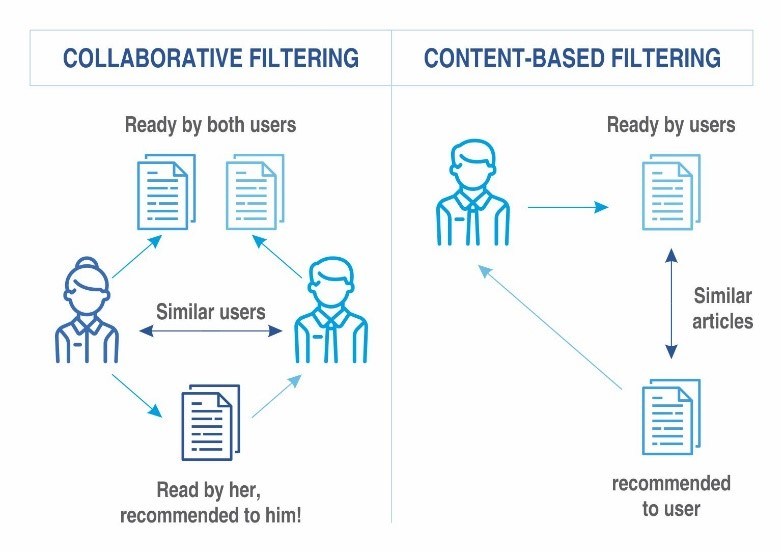
Collaborative Filtering Process
Almost all of these recommendation systems are in use by every major ecommerce player in the world. A quicker, cleaner understanding of these models is a vital skillset valued by the most highly rated and capitalized corporations in the world. The end result, in keeping with the spirit of illustrations of this blog is to view the end result, which can be summarized as below:
To get onboard this exciting domain in the global ecommerce and data driven growth hacking industry, enroll now for one of the world’s most prominent and valued data science programs for individuals!














