
















Data normalization is essential in reorganizing and optimizing the database, and it is widely used in the present era of globalization. This systematic method reduces complexity duplication and increases accuracy by subdividing big files into manageable, small, regular tables. Normalization is reaching a level where the organization can efficiently enhance query performance, storage, and a neat database. It is crucial for organizations dealing with a massive volume of data to understand the peculiarities of data normalization for effective and scalable data management.
The Core Concept of Data Normalization
Data normalization is one of the most crucial database management processes that determines the facility data will take when organized. It entails arranging data to eliminate duplicity and make the overall data more systematic and accurate. It ensures that large, unassociated tables are partitioned into smaller and related ones to reduce anomalies that cause data redundancy
The purpose of data normalization is as follows:
- Ensuring Atomicity: Every data item is kept at its basic level to avoid placing more than one value in a field. This helps increase data accuracy within a database and the information recall rate.
- Maintaining Logical Organization: Data is stored in different tables, each with a well-defined relationship, and they do not occupy an ample space.
- Enhancing Consistency: When making changes or additions, maintaining the coherence of the data becomes easy and effective since related tables are updated simultaneously.
For example, instead of storing customer names, addresses, and orders in a customer database, data normalization will place each group in different tables using unique keys instead of storing customer names, addresses, and orders in one table. This helps manage, understand, and scale the database and data set, resulting in better performance.
How Data Normalization Works in Database
Database normalization can be defined as standardizing the data stored in a database by dividing large tables into small tables to minimize dependency. Its main objective is to reduce redundancy and enhance the organization of data and storage format.
Some of the measures commonly taken to normalize data include the following:
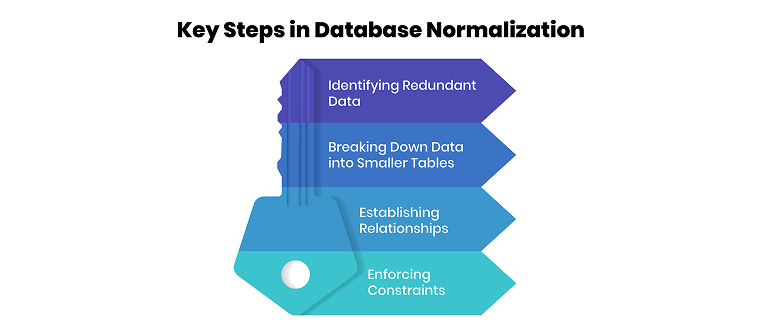
- Identifying Redundant Data: The first activity here is the process of seeking data that is duplicated that exists in the database. This information redundancy leads to inconsistency and increases in errors and creates the problem of the need to store duplicate data. This results in a reduction of clutter in the database, meaning it becomes more efficient in its tasks by getting rid of such redundancies.
- Breaking Down Data into Smaller Tables: Data is divided into several small, logically related tables after identifying redundancy. This approach is effective because each holds information that is easily accessible and can be updated.
- Establishing Relationships: In a normalized database, different tables are linked using keys, such as the primary and foreign keys. These keys help maintain data integrity on many tables. For example, customer details and orders may be stored on two tables, linked together with a foreign key of a customer number.
- Enforcing Constraints: Normalization also includes implementing constraints that control data anomalies. For example, constraints prevent null values from being stored where they shouldn’t or data in one table to be different from that in another.
Exploring the Types of Database Normalization
Data normalization is another crucial process in database design, since it helps those involved avoid data redundancy. Normalization can be defined in several levels that contain specific techniques to enhance data organization in the relational database system.
-
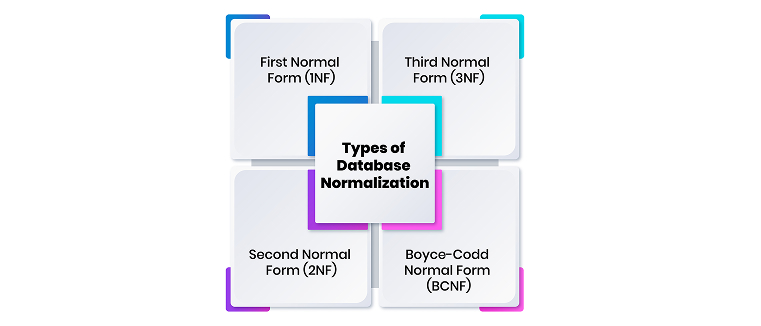
First Normal Form (1NF):
The first process entails analyzing each table in a database and converting its columns into atomic forms—eroticizing the fields so that each can only hold one value. It also eliminates duplicate rows. For example, in the customer table, fields that pertain to several customers should be clustered in different rows with no repeating groups and multi-valued attributes. -
Second Normal Form (2NF):
Building on 1NF, 2NF removes partial dependencies. This means that all other attributes or fields used in the table must rely on the whole of the primary key and not a mere fragment. For instance, if the table contains orders with all the order details in each row and the customer details, the latter should be in a separate table to eliminate partial dependents on the orders table. -
Third Normal Form (3NF):
The third standard form (3NF) extends this by entirely removing transitive dependencies. This means that non-secondary attributes are determined solely by the primary keys and no other secondary attributes. For instance, there is this issue of splitting address info from the customer block to remove excess data contingent on different attributes. -
Boyce-Codd Normal Form (BCNF):
BCNF helps to solve cases that can be in 3NF but have anomalies due to the intersection of candidate keys. It ensures that every determinant in a table is a candidate key, thus achieving better consistency in complicated databases.
Role of Data Normalization in Database Management
Normalizing data is another vital function in improving the functionality and efficiency of a database. It eliminates duplicity, increases data standardization, and minimizes database searching. Now, let's explore key roles:
- Data Consistency: Data normalization also ensures data redundancy and that all related data are placed in one organized table for easy access and applicability. This eliminates issues such as inconsistent updates and enhances data consistency across different databases.
- Query Performance: The normalization technique will require fewer joins, ensuring that specific and relevant information is easily obtained. When database structures are organized well, retrieving the data or performing other queries takes less time.
- Scalability: When the data is enormous, any business experiences more read-and-write operations. Data normalization helps expand databases by managing them, thereby avoiding the issue of having to develop them only to face performance issues.
Data Normalization vs. Denormalization: Striking a Balance
Data normalization and denormalization are two concepts that are quite opposite in the database field. They are used based on the database's needs.
- Normalization, in general, is all about minimizing data duplication and improving data consistency. It ensures that data is stored in a manner that avoids redundancy and that the stored data is standard in the database. Although it results in more excellent storage and increased data quality, it raises the problem of slow queries since multiple joins must be created in tables.
- On the other hand, denormalization intentionally adds redundancy to the database as part of the DBMS design. This approach is typically used to improve read operations in large databases created for reporting or analytical purposes. Since denormalization removes some of the relations, queries are executed in less time and outperform in some cases, but this comes at the cost of increased space complexity and the possibility of data inconsistency.
In the database decision, the role of purpose is the key:
- Normalization is widely used in systems that deal heavily with transactions, such as bank management systems, because data integrity is crucial.
- Denormalization is used in systems that need better query performance, like a data warehouse or large reporting applications.
Industry Applications of Data Normalization
Data normalization is vital to different industries, as it makes databases accurate, minimizes the repetition of data, and enhances the overall efficiency of the database. The good organization of data based on a hierarchy is essential to increase the operational results of distinguished data-holding companies. Organizing big data greatly benefits industries that involve high data analysis and real-time results.
Some of the important uses of data normalization in various industries are as follows:
- Financial Services: Financial transactions in banks and other financial institutions involve documentation that needs to be accurate and standardized. Data normalization leads to issues of duplication of customers’ accounts, standardization of transaction records, and efficient procedures in detecting fraud, as the data in the database is well organized and standardized.
- Healthcare: Medical databases contain records of clients’ demographic details, medical history, and treatment administered to them, together with prescribed medicines. Data normalization guarantees the standard format of electronic health records, eliminating the possibility of developing inaccurate diagnoses or treatment strategies and enhancing information sharing between hospitals.
- E-Commerce and Retail: Retailers manage extensive product catalogs, inventory, and customer databases. Normalizing data helps with better stock management, uniformity of the prices of the same product at different outlets, and effectiveness in managing customer preferences in personalized marketing.
Data normalization has limitations, like making queries more complex, data fragmentation, and poor performance in high-read requests. When a database is overly normalized, many joins are created and managing them lowers database access speed. It is imperative to achieve the optimization between normalization and operation performance.
- Adopt a Hybrid Technique: Normalization should not be accompanied by full denormalization of all tables because it increases the response time while ensuring data correctness. Identifying frequently referred data, and its storage structure assists in attaining balance
- Indexing and Query Optimization: Multiple joins are expensive when creating tables. However, proper indexing helps minimize their effects and improve database speed in data retrieval without affecting the structure. Optimized SQL queries enhance the database's functionality.
- Audit and Maintain Databases: Data auditing should be done periodically to minimize data fragmentation and duplication. Periodically, the efficiency of relationships and dependency pays attention to applying the types of database normalization for long-term use.
Conclusion
Data normalization is essential for a database to be efficient, accurate, and easily scalable. It improves database management by eliminating duplication, helping to fine-tune query processing, and sustaining data integrity. Normalization enhances security and structure; therefore, it is only appropriate to balance normalization and performance. Assessing its benefits for various industries is crucial to improving organizational efficiency. The level of data normalization to use depends on the system requirements and data storage and utilization plans for the future.














